The Day My AI's 'Thinking' Ate 97% of the Token Budget

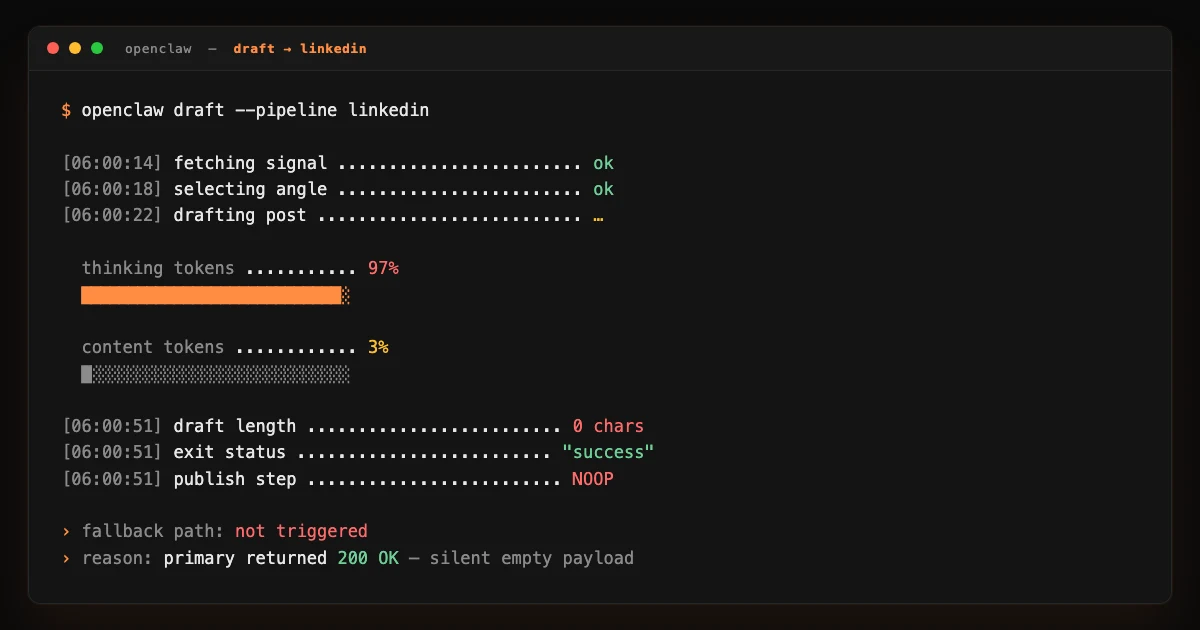
The pipeline ran. The log said success. Nothing posted. Three times in a row.
This is the story of the day I learned that "the model returned an empty string" is a distinct failure mode from "the model returned bad content," and that one of them is much harder to catch than the other.
The Symptom: A Pipeline That Logged Success and Posted Nothing
The first morning I noticed, I assumed the publishing platform's API had hiccuped. It happens. I queued a manual post and moved on.
The second morning I noticed, I started paying attention. The drafting step had clean exit codes. The log entry said the pipeline had run end to end. The publishing step had not been called. Somewhere between draft and publish, the content had disappeared.
The third morning I noticed, I stopped the schedule and dug in.
What Was Actually Happening
The drafting step was using a reasoning model. The kind that thinks out loud before producing an answer. That intermediate thinking is wrapped in tags so it can be stripped out before the final content is sent downstream.
The stripping was working. The problem was that the thinking had consumed so much of the token budget that almost nothing was left for the actual answer. The model was producing a long, thoughtful internal monologue, hitting the budget ceiling, and returning a near-empty content payload. The strip step then removed the thinking and left a string with effectively no content in it.
The pipeline checked whether the model call had succeeded. It had. The pipeline did not check whether the resulting content was long enough to actually be a post. So a clean exit with an empty body sailed straight through every gate downstream until the publishing step refused to do anything with a zero-length string and quietly returned without an error.
I want to say I noticed this in an hour. I noticed it after three failed publishing days, two confused log readings, and one read of the raw model response that I had been skipping because the exit codes were green.
The Fix in Principle
The fix had three parts.
First, raise the ceilings. Reasoning models need much more room than non-reasoning models for the same final output length. The number I had been using was correct for a non-reasoning version of the same model. It was not even close for a thinking version. Doubling the ceiling fixed the immediate issue.
Second, lengthen the timeout. A reasoning model takes longer to respond, and a generous timeout that was reasonable for the non-reasoning version was starting to bite on the thinking version. Doubling the timeout fixed the secondary issue.
Third, and most important, validate the output. The pipeline now refuses to call publishing with a payload below a minimum length. If the draft is below the threshold, it logs the failure and tries the fallback path. This is the kind of check that should have existed from day one. I did not write it because I had not anticipated a model returning empty content cleanly.
The lesson is in that last part. Failure modes you have personally experienced get handled. Failure modes you have not experienced get to bite you exactly once before you write the check for them.
Why the Fallback Path Was Worse Than No Fallback
Here is the part that hurt.
The pipeline had a fallback model already wired up. It was supposed to be the safety net for exactly this kind of situation: primary provider goes weird, fallback provider takes the slot, pipeline ships anyway. The fallback existed. The fallback was logged. The fallback never ran.
The reason it never ran: the fallback only fired on a hard error from the primary. An empty content payload was not a hard error. The primary was technically succeeding. The fallback was waiting for a failure that, structurally, could not happen as long as the primary was returning two hundred OK with a body of any length, even a length of zero.
A fallback that triggers on the wrong condition is worse than no fallback at all. It creates the appearance of redundancy without the substance. The system thinks it is resilient. The operator thinks it is resilient. Nothing is resilient. The first real failure walks straight through.
I rewired the fallback to trigger on validation failure rather than on transport failure. Now an empty content payload is a failure the fallback can see, and the fallback actually runs.
The Meta-Lesson: Test the Failure Modes You Designed For
There is a version of this story that ends "and that is why I now have monitoring." I do not really believe that version. Monitoring would have shown me the same green exit codes I was already getting. The lesson is not "add monitoring." The lesson is something more uncomfortable.
If you designed a fallback path, you have to test it under the actual failure conditions you designed it for. Not under the failure you imagined. Under the failure that will actually happen. The two are usually different.
Before this failed in production, I would have told you with full confidence that my fallback path was tested. What I meant was, "I have run the fallback manually by faking a hard error from the primary." That is not testing the fallback. That is testing the manual fallback path. The real fallback was the one that needed to fire when the primary returned an empty body, and that path had never been exercised at all.
I now keep a small list of "weird failures I have actually seen in production." Every time a new one shows up, I add it to the list, and I write a test that reproduces it deterministically. The test is the second-cheapest thing in the world. The bug that bit me three mornings in a row was much more expensive than the test ever would have been.
If you are running an automated content pipeline, or honestly any automated pipeline, do me a favor and check today whether your drafting step can return a clean success with no content. If it can, your fallback path probably is not protecting you from the thing it should be protecting you from.
I would rather you find that out by reading this post than by checking your feed on Friday and realizing nothing has gone out since Monday.
More notes
Building Openclaw: One Agent, Many Pipelines, Zero Mondays at a Blank Doc
Why I stopped trying to be consistent on my own and built an agent to run my owned-media operation instead. The boundary between me and Openclaw, and what it actually catches.
AI ToolsAI Vendor Lock-In Is the Real Risk Right Now: 3 Smart Moves to Make
Anthropic is running Microsoft's old playbook on AI subscriptions, and the bill is coming. Here's what to do before AI vendor lock-in catches everyone flat-footed.
AI ToolsGLM 5.2 Review: My Honest Take After Daily Use vs Opus 4.7
A GLM 5.2 review after daily use against Opus 4.7, including migrating Draftly.blog across WordPress, Vite, and Next.js. The closest thing to Claude at any price.
AI ToolsLimit Testing: How One Valorant Habit Taught Me Exactly What AI Is Good and Bad At
Limit testing is a Valorant habit where you push a skill until it breaks. Here's how it taught me piano, writing, and exactly what AI is good and bad at.