GLM 5.2 Review: My Honest Take After Daily Use vs Opus 4.7
A GLM 5.2 review after daily use against Opus 4.7, including migrating Draftly.blog across WordPress, Vite, and Next.js. The closest thing to Claude at any price.

 Opus 4.7 in Claude Cowork on the left. GLM 5.2 in opencode on the right. Same kind of task, different price tag.
Opus 4.7 in Claude Cowork on the left. GLM 5.2 in opencode on the right. Same kind of task, different price tag.
A few months back I wrote a Minimax vs GLM retrospective and called GLM 5.1 a serious coding model at a price that felt almost unfair.
GLM 5.2 dropped. I rolled it into my daily setup. Same verdict, only stronger.
If you're paying for Opus 4.7 and the bill is starting to bug you, this is the model to run next to it. Here's my GLM 5.2 review after a couple months of real production work.
What Changed Since My Last GLM Post
Three things moved.
First, GLM 5.2 actually shipped, and it's a real generational jump on 5.1. Coding is sharper. It follows through on long tasks better. And it has a 1 million token context window now, which I'll come back to, because it matters more than the version bump.
Second, my test got harder. Last time I was running my portfolio site on GLM 5.1 through opencode. Now I'm using 5.2 to manage Draftly.blog, both the headless CMS and the vibe-coded app. It's been migrating that stack across WordPress, Vite, and Next.js without dropping the thread. That's not a gentle workload for a cheap model.
Third, I'm holding it against Opus 4.7, which is what I run in Claude Code. Sonnet 4.6 too, when I need speed. GLM has to feel close to those or it stays a backup. Right now it's earned a daily spot.
The Real Test: Draftly.blog Across Three Stacks
Draftly started on WordPress, got rebuilt as a Vite prototype, and now lives on Next.js. That kind of move is brutal for any model, because the patterns don't carry over. WordPress thinks in templates and hooks. Vite thinks in modules. Next.js wants server components and route segments. Most agents that hold one of those mental models fall apart the second you cross into another.
GLM 5.2 held up. It kept the CMS layer and the app layer straight at the same time, called the right shots on what to port and what to throw out, and did most of it while I was off doing other work. That's the part that keeps surprising me. It's gone from answering questions about code to actually running the work.
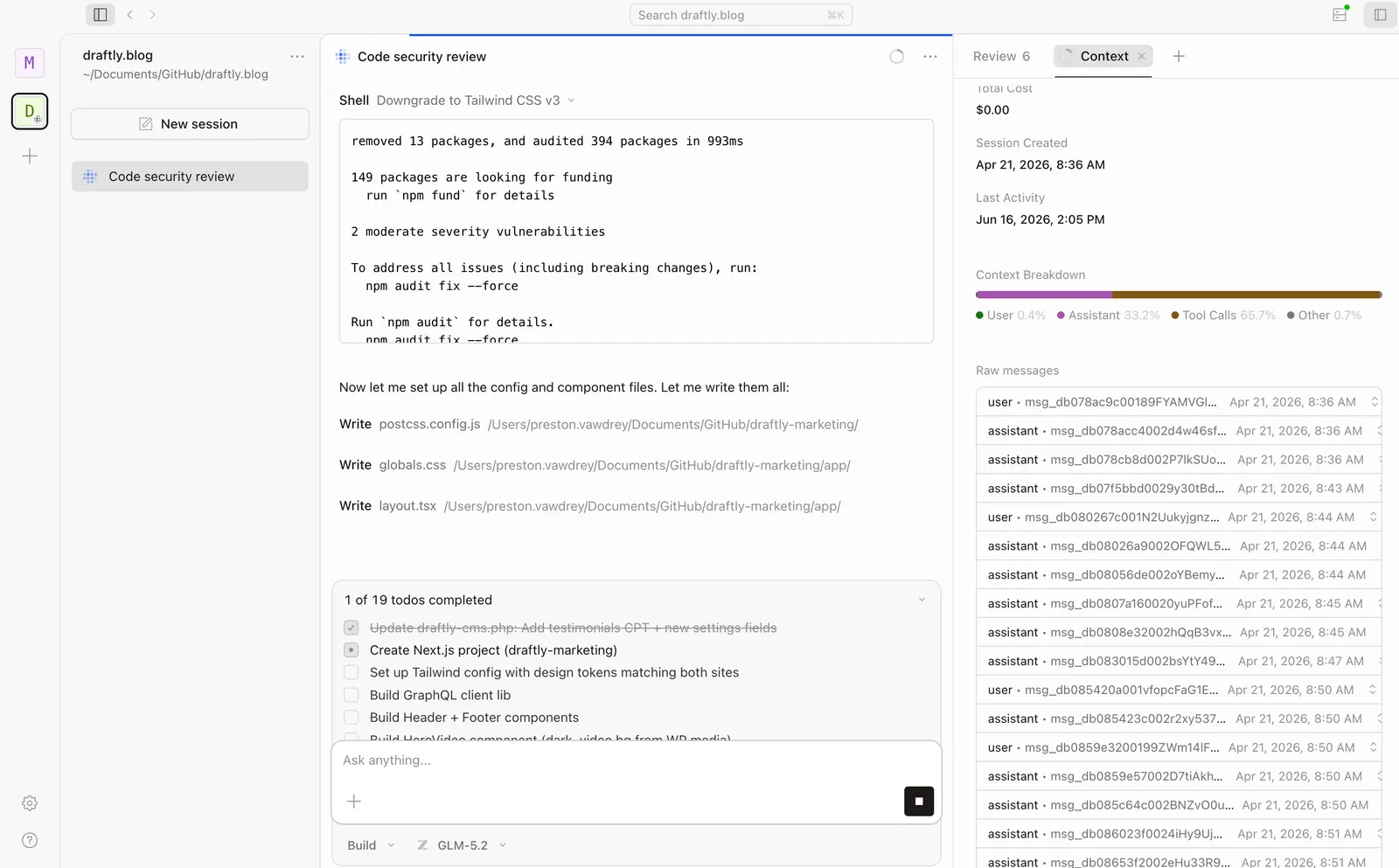 A GLM 5.2 session on Draftly.blog inside opencode. The Context panel on the right is where the 1M window earns its keep.
A GLM 5.2 session on Draftly.blog inside opencode. The Context panel on the right is where the 1M window earns its keep.
I won't oversell it. Opus 4.7 would've done the same migration in fewer prompts and left a cleaner middle state. But GLM 5.2 finished, and it didn't need me hovering over every step. At this price, that's the bar that counts.
Why GLM 5.2 Punches Above Its Weight
You could tell a story where GLM 5.2 is just a great model and leave it there. I think two parts of the setup carry as much weight as the model.
The harness carries a lot. I run GLM through opencode, and opencode feels like Claude Code. Same tool loop, same context handling, same vibe while you work. Coming from Claude Code, the muscle memory just transfers. That alone papers over a lot of the gap between models, because the agent loop is doing as much work as the tokens.
The MCPs carry a lot too. The GLM coding subscription ships with MCP servers that are actually good. File tools, search, the connectors I'd reach for in Claude. I didn't have to bolt together a tool layer to match what I'm used to. It matched out of the box.
And the 1M context window matters more than I expected. The Draftly migration touches the whole CMS schema, the old WordPress export, the new Next.js routes, and a stack of integration files. On 200K I'd be chunking and re-chunking all day. On a million, I hand it the project and ask. Once you work that way, going back to a small window hurts.
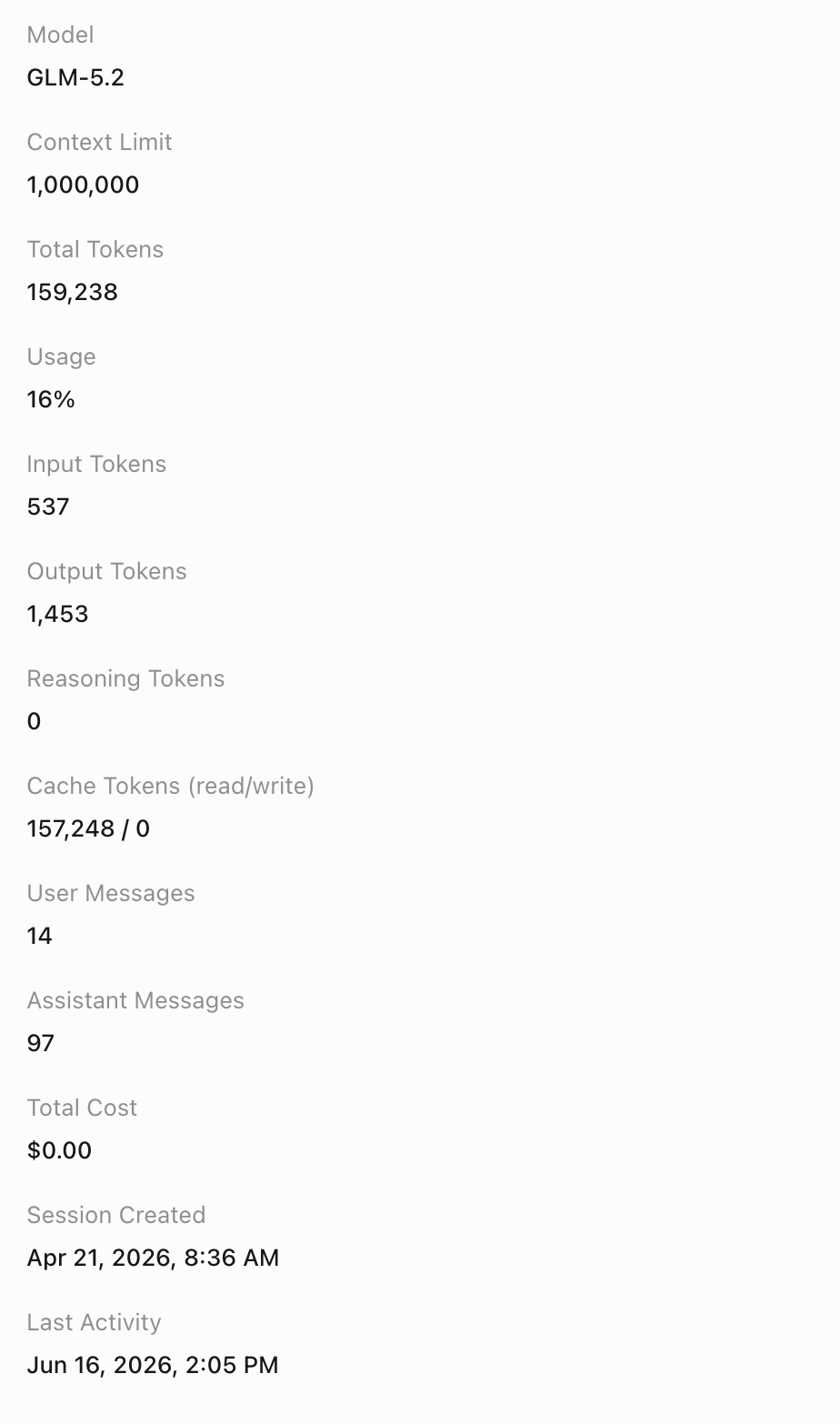 A real session from the Draftly work: 159K tokens deep into a 1M window, with 14 user messages and 97 assistant responses still in scope. That's the mode of work the bigger window unlocks.
A real session from the Draftly work: 159K tokens deep into a 1M window, with 14 user messages and 97 assistant responses still in scope. That's the mode of work the bigger window unlocks.
The Pricing Used to Be Almost Unfair (Buyer Beware)
I'm grandfathered into a legacy Z.ai coding plan at $81 a quarter. That price has more than doubled lately. Back when I wrote about GLM 5.1 the math was cleaner. At my rate it's still cheaper than Opus on usage billing, but the deal isn't what it was, and new buyers pay more than I do.
If you're shopping Z.ai today, here's the thing to sit with. Prices can move on you mid-subscription. I got hit by one of those jumps. The Reddit threads will show you how often it's happened to other people. Assume the number you sign up for this quarter could be different next quarter. That comes with buying into a Chinese AI provider in 2026.
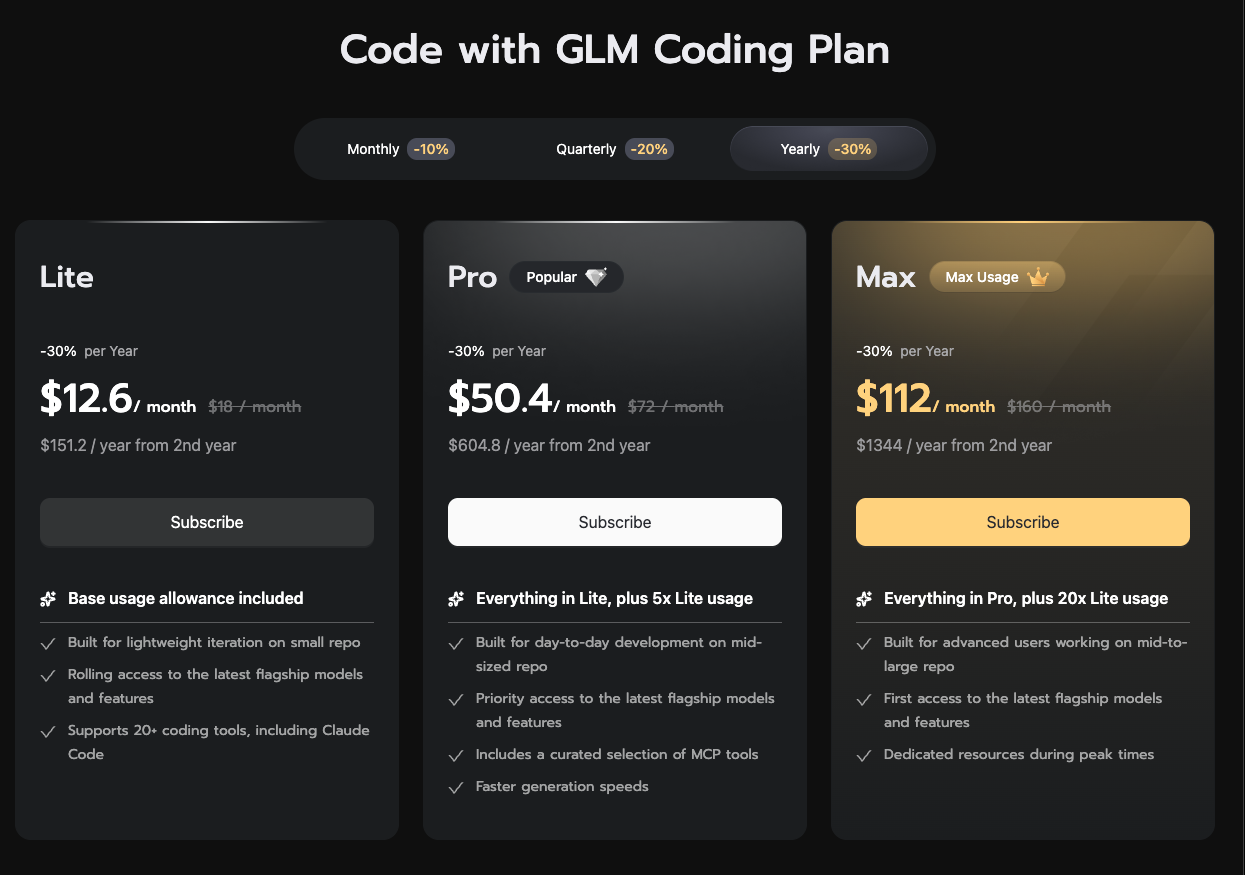 Z.ai's current public pricing. My grandfathered $81 a quarter sits well under the Pro tier. New buyers don't get my deal.
Z.ai's current public pricing. My grandfathered $81 a quarter sits well under the Pro tier. New buyers don't get my deal.
Even with the volatility, the day-to-day is that I'm getting a Claude-shaped tool for what one or two heavy Opus days would cost on usage billing. For a side project like Draftly with no revenue to justify Claude-grade spend, that math is the whole game. Just go in with eyes open.
Is Z.AI Reliable? (And How I Work Around It)
Reliability is the other catch. Z.ai has had ongoing connectivity issues and the occasional full outage. It's annoying, I won't pretend otherwise. When their servers drop mid-task, whatever you're building stalls.
The fix is the one from my Minimax post. Run GLM through OpenRouter instead of Z.ai directly. The Z.ai coding plan still applies, you get the same model, and the front door is steadier. Since switching I've had basically zero downtime. Putting GLM into any unattended workflow? Route through OpenRouter on day one.
I Just Canceled My Minimax Subscription
Quick side note. In the Minimax vs GLM post I ran a split-brain setup, Minimax orchestrating and GLM coding. Right call then. Not anymore.
GLM 5.2 through OpenRouter does both jobs well enough that I dropped Minimax. Orchestration on 5.2 isn't quite Minimax 2.7 at its best, but it's close, and running one model on one provider is worth the small step down. One subscription, one model, one tool loop. That's the setup I want to live in.
Where Opus 4.7 Still Wins
I'd be lying if I called GLM 5.2 a tie. Opus 4.7 still wins on a few things I won't give up for paid client work:
- Nuance on vague prompts. Opus asks the right clarifying question. GLM just starts building.
- Code review and refactors. When I want a second set of eyes on a tricky change, Opus catches more.
- The feel of the output. Opus reads like a careful senior wrote it. GLM reads like a fast junior. Both ship.
For Draftly, where I'm the QA loop, GLM is plenty. For client work I'm still on Opus 4.7 in Claude Code. Right tool for the cost.
My Backup Plan If Claude Goes Away
The honest test of any number-two model is what you'd run if number one vanished. If Claude Code and Claude Cowork disappeared tomorrow, I'd be on GLM 5.2 through OpenRouter, in opencode, on the Z.ai plan. I'd keep working and I wouldn't panic.
Keeping a number two warmed up isn't just a hedge against outages, either. It's the escape hatch I argue everyone should have in AI vendor lock-in, for the day the subsidized pricing stops being subsidized.
That's the strongest thing I can say about a model that runs me about $27 a month. If you've got an always-on agent, a side project, or you just want to see what the Claude alternatives look like in 2026, start here.
Running GLM 5.2 in production? I'd love to hear how it's holding up for you. Drop me a note on LinkedIn.
More notes
 AI Tools
AI ToolsLimit Testing: How One Valorant Habit Taught Me Exactly What AI Is Good and Bad At
Limit testing is a Valorant habit where you push a skill until it breaks. Here's how it taught me piano, writing, and exactly what AI is good and bad at.
 AI Tools
AI ToolsThe Day My AI's 'Thinking' Ate 97% of the Token Budget
A debugging story about a pipeline that logged success and posted nothing. The culprit: a reasoning model that consumed almost the entire budget on intermediate thinking before the content tokens fired.
 AI Tools
AI ToolsSiri AI VS ChatGPT: Why Apple Should be Scaring OpenAI
Apple's Gemini-powered Siri AI matches paid ChatGPT for most things real people use it for. The Siri AI vs ChatGPT shift will eat the free tier and pressure the $20 paid one too.
 AI Tools
AI ToolsBuilding Openclaw: One Agent, Many Pipelines, Zero Mondays at a Blank Doc
Why I stopped trying to be consistent on my own and built an agent to run my owned-media operation instead. The boundary between me and Openclaw, and what it actually catches.