What a Spam Audit Taught Me About Shipping AI Content at Scale

I run MushroomPro through an agent-driven AI publishing pipeline. Openclaw handles topic selection, on-page polish, and publishing; the Draftly drafting engine handles research-to-draft. The pipeline pulls signal from a curated set of sources, drafts an article, generates a header image, picks a category, and pushes the result to WordPress. It has done this on a regular schedule for the better part of a year. The site grew. The traffic grew. The pipeline kept doing its thing.
Then Google noticed.
This is the story of the audit I ran when I saw the first signs, the bugs I found that had nothing to do with AI quality, and the loop I now run on every AI publishing pipeline I touch.
The Audit That Started It
The signal that something was wrong was not a manual penalty. It was a drift in the kind of traffic the site was getting. Branded queries held. Long-tail informational queries that the site had been doing well on started softening. The pattern matched what I have seen on other sites where Google starts quietly applying a spam classifier to the content.
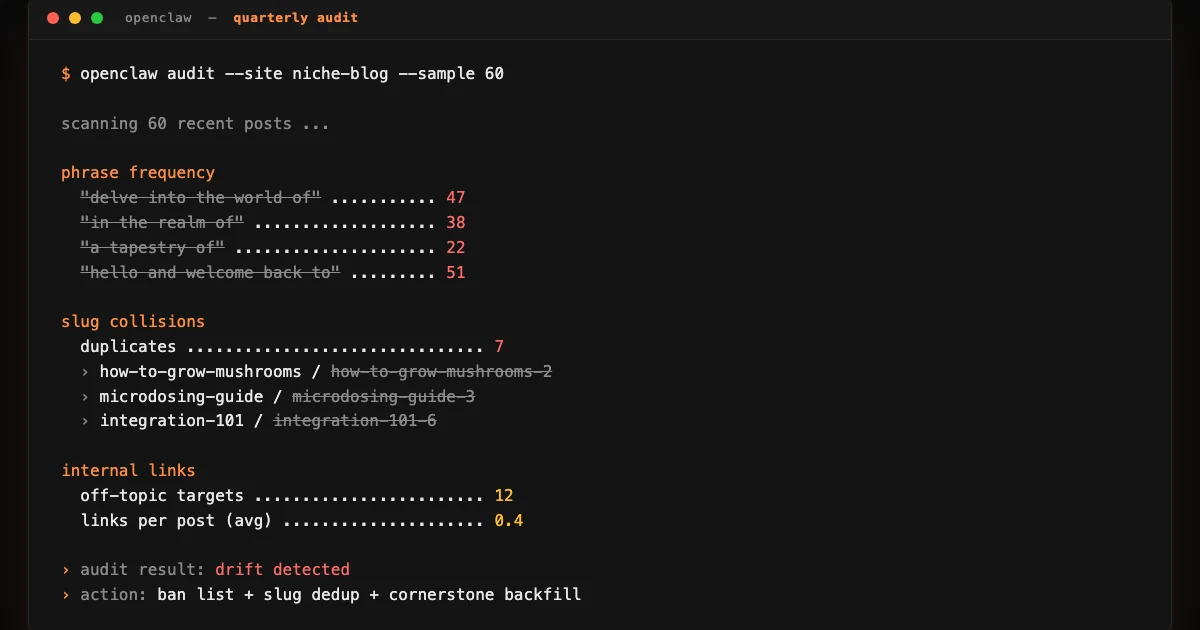
I pulled a sample of recent posts. Reading them with fresh eyes was the most humbling part of the whole exercise. The posts were not bad. They were also unmistakable. There were phrases showing up across dozens of posts that were the exact phrases I have seen flagged in every AI-content guide for the past two years. I had read those guides. I had even put a banned-phrase list into my own LinkedIn pipeline. I had not put one into this one. The drift had been quiet and consistent over months.
The Tells: How Google Spots AI Content
If you have not done one of these audits, here is the surface area that matters.
Phrases that show up across a body of content at a frequency that no human writer would produce naturally. The classic ones are "delve into," "in the realm of," "a tapestry of," and variants that include the word "realm" or "tapestry" doing work no human ever asked them to do. None of these phrases are inherently bad. The pattern is the frequency.
Openings that all read the same. Every post starting with the same kind of hello-and-welcome-back-to-the-site move. Human writers do this sometimes. AI writers do this every single time unless you stop them.
Structural sameness. Every post the same length. Every post the same number of headings. Every post the same kind of conclusion paragraph. A human content team produces variation by accident. An AI pipeline produces uniformity by accident.
Internal linking that does not actually link to anything related. This was the one I missed for the longest. I had told the pipeline to add internal links. It was adding them. It was adding them to whatever it picked first that matched the loosest keyword overlap. The links existed and pointed nowhere useful.
Duplicate or near-duplicate content. This was the one that surprised me.
The Slug-Collision Bug That Doubled My Duplicate Content
The pipeline generated slugs from titles. Two posts with similar titles produced similar slugs. The publishing platform, when it saw a slug already in use, appended a numeric suffix and published the new post anyway. Numbered duplicates of titles I had already published were quietly racking up over months. The pages were ranking against each other on the long-tail queries the site cared about.
The fix was to deduplicate against the full publishing history, not against the recent window I had originally checked. The reason this had not surfaced earlier is that the dedup check was looking at the last thirty days. Anything older than that was invisible to the check. The site had enough history that the assumption "nothing older than thirty days would ever collide" was no longer true.
I cleaned up the duplicates by hand. There were not as many as I feared, but there were enough that the cleanup itself was a real day of work. The fix in the pipeline took about an hour.
What I Did About It
The full intervention had four parts.
A banned-phrase list got added to the drafting step. Every phrase I had read about in the AI-content guides went on the list. A few that I had personally caught in my own audit went on too. Drafts that contain a banned phrase get rejected and redrafted.
The opening structure got loosened. Instead of a single template, the pipeline now picks from a small library of opening shapes, and the rubric requires the first sentence to be specific to the actual article rather than a generic welcome.
Internal linking got rebuilt to look at semantic overlap with existing posts, with a minimum threshold below which the link does not get added at all. A post with no good internal link to make now just does not get an internal link, which is correct.
Cornerstone content got written. Four long, deeply researched posts on the topics that anchor the rest of the site. These are the posts I would have written by hand if I had infinite time. The pipeline did not write them. I did, over a few weeks of evenings. They serve as the gravitational center the rest of the content links into.
The traffic recovered within about a month. The recovery was not dramatic. It was steady. The site stopped getting penalized for being an AI farm and started getting credit for being a useful resource on a real topic.
The Audit Loop I Now Run Like Negative Keywords
The real lesson from this is the audit cadence.
If you have ever run paid ads, you know that a healthy account needs a regular negative keyword sweep. Not because the campaigns are bad. Because every campaign drifts toward irrelevance over time, and the only thing that keeps it tight is someone going in and pruning. The exact same thing is true of an AI publishing pipeline.
I now run a quarterly audit on every AI publishing pipeline I operate. I pull a sample of recent posts. I read them with fresh eyes. I check for banned-phrase drift, structural sameness, slug collisions, broken internal links, and orphan posts that nothing links into. Anything I find goes into the rubric, into the banned-phrase list, or into a one-off cleanup task.
The audit is not the kind of work that compounds. It is the kind of work that prevents the compounding work from quietly going to waste.
If you are publishing AI content at any kind of scale, this is the part nobody talks about and the part that actually matters. The drafting model is rarely the problem. The pipeline around the drafting model, left unaudited for long enough, always is.
More notes
GEO vs SEO: Why GEO Optimization Advice Is Mostly Noise
GEO vs SEO is a false debate. GEO is just a data layer built on top of existing SEO. Here's what actually gets your content cited by AI systems.
SEOHow Local SEO Drives Patients to Dental Practices
A behind-the-scenes look at how comprehensive local SEO strategies have helped dental practices in Arizona attract thousands of new patients.
SEOWhat Actually Matters About AI Search for Your SEO
Most GEO advice is recycled SEO with new buzzwords. A couple of things about AI search do genuinely matter though. Here's what's signal and what's noise.
SEOBest Books on SEO Marketing in 2026 (From a Working SEO)
The best books on SEO marketing in 2026, picked by someone who runs SEO for clients every day. Two for first-timers, three for working marketers who want depth.